Title here
Summary here
May 13, 2026 by Victor M. Alvarez4 minutes
Almost a year ago, we published a blog post titled YARA-X just got smarter. It described some improvements aimed at making life easier for our users. Today, we are publishing a similar entry, but this time it focuses on performance improvements rather than usability.
While YARA-X has consistently offered robust performance, two major recent
changes—PR #654 and
PR #657—introduce
groundbreaking optimizations to core pattern matching and rules that make heavy
use of the matches operator.
Here is a deep dive into how these performance gains were achieved.
When searching for hundreds of thousands of byte strings simultaneously, YARA-X relies on the Aho-Corasick algorithm. This is the primary workhorse of the YARA-X scanning engine.
Previously, YARA-X utilized the widely used
aho_corasick crate, a robust
and performant implementation of the Aho-Corasick algorithm in Rust. However,
PR #654 replaces aho_corasick
with daachorse, a much faster
implementation built around a compact double-array trie data structure.
Conceptually, the implementation in daachorse mirrors the core design
principles of the original C-based YARA engine. Its performance gains over the
standard aho_corasick crate stem from two primary architectural advantages:
Tighter inner loop: Byte-by-byte traversal through NFA transitions requires fewer memory indirections and branching instructions.
Cache-efficient storage: The double-array automaton layout optimizes memory locality, drastically reducing CPU cache misses during intensive scanning over large files.
Migrating to daachorse had its own challenges, though. To facilitate a
seamless transition and ensure YARA-X’s matching semantics were fully
preserved, upstream contributions were made to daachorse to align its
API closer to the familiar aho_corasick crate. Most notably,
PR #128 added
support for Aho-Corasick automatons with duplicate patterns or no patterns
at all.
Using the full rule set from YARA Forge across
a corpus of 500 random VirusTotal files (totaling ~24GB), daachorse achieved
remarkable benchmark results:
| Scanner | Scan Time | Speedup |
|---|---|---|
| YARA-X (daachorse) | 26.152s | — |
| YARA-X (aho_corasick) | 57.584s | YARA-X with daachorse is 2.20x faster |
| YARA (legacy) | 48.275s | YARA-X with daachorse is 1.85x faster |
This brings YARA-X up to speed with legacy YARA in terms of performance. Now, we can guarantee that YARA-X is faster than YARA in almost all cases, with very few exceptions.
Starting with YARA-X v1.16.0, you can enjoy this improvement.
When authoring complex YARA rules, analysts frequently evaluate a single
variable, structure field access, or module output against dozens of distinct
regular expressions inside an or condition. A common example we had
observed in VirusTotal is inspecting domain names or URLs:
condition:
vt.net.domain.raw matches /evil-c2\.com/ or
vt.net.domain.raw matches /phishing-login\.net/ or
vt.net.domain.raw matches /malicious-dga[0-9]{4}\.org/The example above is only for illustrating the point; in real life, we have seen
rules with hundreds of matches operations like these.
Previously, YARA-X evaluated each matches expression sequentially. If a rule
contained fifty regex checks against the same field, the scanning engine would
execute fifty separate passes over the target string.
PR #657 introduces an advanced
compiler optimization that detects identical match targets within or
conditions and automatically groups their regular expressions into a unified
RegexSet.
A RegexSet is a specialized feature of the standard Rust
regex crate designed precisely to speed
up the matching of a single string against multiple regular expressions at the
same time.
When regular expressions are evaluated sequentially, the scanning engine incurs repeated overhead: it must re-initialize its search state and scan the entire target string from beginning to end for every single pattern. As rule complexity grows, this redundant scanning becomes a major performance bottleneck.
By grouping these expressions into a RegexSet, the compiler combines all
individual regular expressions into a single, unified state machine
(automaton). When a target string is inspected, the scanning engine executes
exactly one scan pass over the data. As it steps through each character in
the target string, the unified state machine simultaneously tracks and evaluates
potential matches for all grouped regex patterns at once.
This optimization shifts the scanning complexity from scaling linearly with the number of regex patterns to a single, highly efficient pass over the input string, delivering a huge speed improvement when executing complex rule sets.
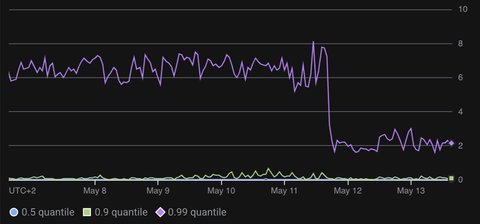
This improvement will be released in the upcoming YARA-X v1.17.0. However, we have already deployed these changes to VirusTotal Livehunt and observed a dramatic drop in scanning time for domain-related rules. The 99th percentile execution time was cut in half, dropping from an average of over 6 seconds to less than 3 seconds. In other words, 99% of rule evaluations now complete in under 3 seconds, whereas they previously exceeded 6 seconds. Additionally, the CPU costs associated to running this workload was also cut in half.